Paper Summary: A Simple Framework for Contrastive Learning of Visual Representations
Context
Unsupervised learning is a framework for learning patterns in unlabeled data. Traditionally, when we think about unsupervised learning, we think about clustering like K-means, DBSCAN, etc. Until recently, with the advancements of Deep Learning, there has been a renaissance of unsupervised learning: from autoencoder to autoregressive networks, variational autoencoder and generative adversarial networks. Even now it is rebranded as self-supervised learning.
I Now call it “self-supervised learning”, because “unsupervised” is both a loaded and confusing term. In self-supervised learning, the system learns to predict part of its input from other parts of it input - Yann Lecun
Self-supevised Learning
Self-supervised learning employs clever tricks so that the data could create its own supervision. It exploits the signal in a large amount of unlabeled data to learn rich representations.
The key ingredient of self-supervised learning is the pretext task or auxilary task. Generally these tasks have some forms of reconstruction of input. In NLP, we have seen it in
-
Word2vec: learning to predict surrounding words given context words -
BERT: learning to predict masked words given context words (Devlin et al 2018)
In Computer Vision:
-
Context encoders: predict the missing part of images (Pathak et al 2016)
SimCLR
SimCLR is the work of Google Brain that follows the line of research of applying contrastive framework into learning representation in Computer Vision (MoCo, PIRL).
The general idea is to use data augmentation to create different versions of the same example then to apply consistency training to ensure these augmented samples share the same label. The consistency training assumption is that if our data augmentation is of high quality (class-preserving data augmentation) then the augmented versions should share the same underlying labels. This assumption is reasonable and common in recent work in semi-supervised learning which employs high-quality augmentations to regularize training (FixMatch, UDA).
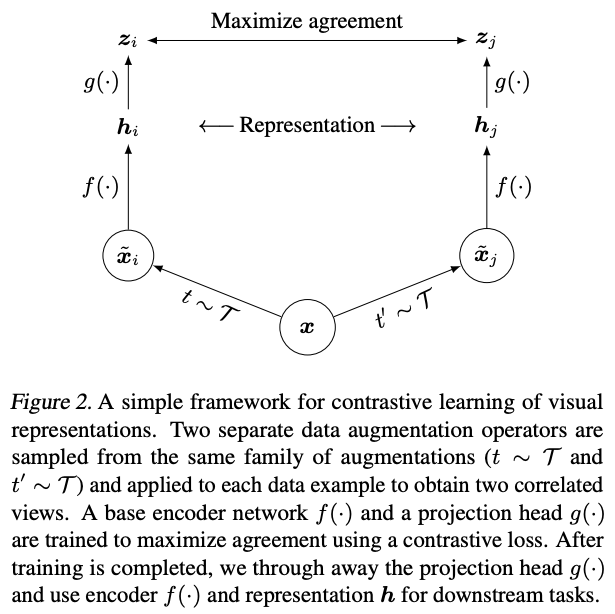
SimCLR consists of the following steps:
-
Data Augmentation: Apply high-quality data augmentation to input x to produce a pair of augmented samples -
Encoding: Run the examples through an encoding function (ResNet-50) to have atransformation-rich representationh -
Projection: Project h totransformation-invariant representationz -
Contrastive Learning: Representations going through a similarity measure (cosine) then propagated to a loss, which is minimized so that similar pairs are pulled together while dissimilar pairs are pushed away.
Once the model is trained on the contrastive learning task, it can be used for transfer learning. The representations from the encoder h are used instead of representations obtained from the projection head.
Result

This is where it gets exciting
On ImageNet: A linear classifier trained on self-supervised representations matches Supervised ResNet50 (76.5% top-1, a 7% relative improvement over previous SOTA)
Basically it says that self-supervised learning models could match performance of their supervised counterparts (Of course, by using larger models and more data). Since we have way more unlabeled data than labeled ones, self-supervised learning could potentially surpass supervised learning in the near future.
Key ideas:
-
Composition of data augmentation is critical for learning good representations
-
Projection head separated from the encoding function: it enables the model to learn transformation-rich representation. This nonlinear transformation boosts accuracy by at least 10%.
-
Contrastive learning framework employs
normalized temperature-scaled cross entropy loss. This loss has similar structure tonpair losswhich has been shown to be a powerful loss in contrastive learning. In the paper, experiments indicate that it boosts performance by +10% accuracy compared to simple margin loss.
Overall, SimCLR is a good paper. In addition to a strong empirical result, it’s interesting to see ideas from different subfields of ML incorporated in this paper, from self-supervised to contrastive learning and semi-supervised learning.